


Trí tuệ nhân tạo vẫn cần tiếp tục nghiên cứu, hoàn thiện - Ảnh: Networkerstechnology
Không dễ có "quả ngọt"
Đại dịch COVID-19 là một cuộc khủng hoảng y tế chưa từng có tiền lệ trong lịch sử nhân loại. Để ứng phó với nó dưới áp lực tốc độ thời gian, giới khoa học đã phải nỗ lực hết sức đẩy nhanh tiến độ các công trình nghiên cứu, thử nghiệm. Thực tế, sẽ không quá khi nói rằng trong hơn một năm qua nhiều lĩnh vực nghiên cứu khoa học khác đã được giảm bớt ưu tiên để dồn sức cho cuộc chiến chống đại dịch.
Hàng ngàn công trình nghiên cứu ứng dụng AI chống COVID-19 đã được khởi động trên toàn thế giới. Và cũng giống nhiều "cuộc tìm đường" khác của khoa học nhân loại, để tới được những mùa quả ngọt hiếm hoi, lĩnh vực nghiên cứu này cũng đã chứng kiến rất nhiều sai sót, thất bại, lầm đường bên cạnh một số thành công.
Tháng 3 năm nay, một nhóm nghiên cứu tại ĐH Cambridge (Anh) công bố báo cáo khoa học đáng chú ý trên tạp chí Nature, trong đó chỉ ra những sai sót thường mắc phải của các mô hình AI trong dò tìm và chẩn đoán bệnh COVID-19 bằng ảnh chụp tia X phần lồng ngực và ảnh chụp CT người bệnh. Họ đã độc lập kiểm tra hơn 400 mô hình AI và phát hiện nhiều khiếm khuyết cần cảnh báo.
"Thật kinh ngạc khi có quá nhiều sai sót về phương pháp nghiên cứu như vậy" - ông Ian Selby, bác sĩ X-quang và là một tác giả của nghiên cứu này, nói với trang Statnews.
Hơn 400 công trình nghiên cứu này gồm cả các nghiên cứu đã xuất bản và báo cáo sơ bộ (còn gọi là "preprint" - một dạng thức tự công bố trước khi in tạp chí) trong giai đoạn từ 1-1 đến 3-10-2020, đều đi theo hướng nghiên cứu phát triển các hệ thống machine learning dành cho chẩn đoán và tiên lượng bệnh COVID-19 từ hình chụp tia X hoặc chụp CT.
Kết quả thẩm định cho thấy các thuật toán thường được đào tạo trên số lượng mẫu nhỏ, dữ liệu chỉ có một nguồn và không đa dạng. Chưa kể, một số thuật toán còn sử dụng cùng một nguồn dữ liệu cho cả giai đoạn đào tạo lẫn thử nghiệm, một sai sót nghiêm trọng có thể dẫn tới ảo tưởng về hiệu quả ấn tượng của hệ thống.
Chứng kiến những sai sót và tình trạng nhập nhằng của các mô hình AI đó, dù là người rất tin tưởng tiềm năng lâu dài của AI, ông Selby phải thừa nhận ông thấy cần cẩn trọng hơn khi thẩm định các báo cáo nghiên cứu được công bố trong lĩnh vực này.
Nhóm khoa học của ĐH Cambridge còn phát hiện nhiều nghiên cứu không những thiếu khâu thử nghiệm hệ thống với các nguồn dữ liệu bên ngoài, mà còn phớt lờ việc công khai cụ thể các nguồn dữ liệu đã sử dụng, hay cách thức đào tạo các mô hình AI của họ.
Chỉ 62 trong số hơn 400 báo cáo có thể vượt qua được vòng thẩm định chất lượng ban đầu của nhóm nghiên cứu vì những thiếu sót và lầm lẫn khác. Và ngay cả trong số 62 công trình đó vẫn có tới 55 báo cáo còn các sai sót như lệ thuộc vào các bộ dữ liệu chưa chuẩn xác.
Một vài mô hình AI được đào tạo để chẩn đoán các ca COVID-19 ở người lớn tuổi bằng hình chụp X-quang nhưng lại được thử nghiệm bằng hình ảnh các bệnh nhân nhi bị viêm phổi.
Những vấn đề này không chỉ xảy ra với các nghiên cứu ứng dụng AI trong ứng phó COVID-19 mà còn ở nhiều lĩnh vực ứng dụng khác.
Danh sách các nghiên cứu chỉ dựa vào nguồn dữ liệu hạn chế hoặc chất lượng thấp đang ngày càng dài ra. Các nghiên cứu đó không nêu rõ phương pháp đào tạo thuật toán cũng như các phương pháp thống kê đã vận dụng, và cũng không thử nghiệm xem liệu nó có hoạt động hiệu quả với những người thuộc các nhóm chủng tộc, giới tính, độ tuổi và ở các vùng địa lý khác nhau không.
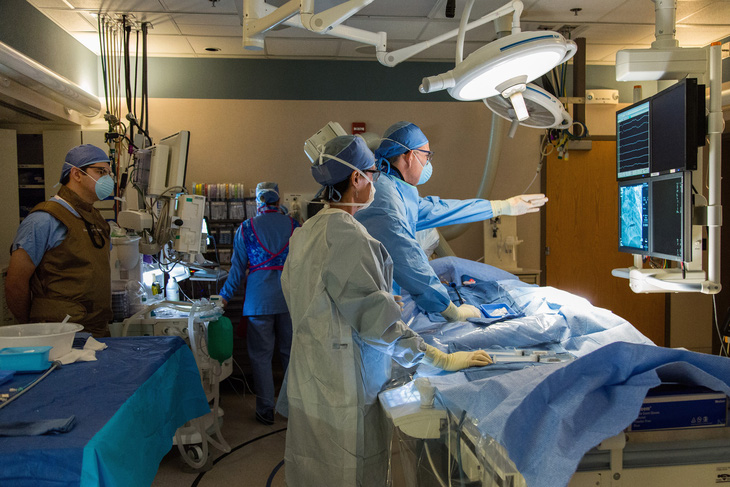
Kỹ sư machine learning Zachi Attia (trái) quan sát trong khi bác sĩ Paul Friedman đặt máy tạo nhịp tim cho người bệnh tại Bệnh viện Mayo Clinic - Ảnh: STAT
Dữ liệu - vấn đề nan giải nhất
Những sai sót, hạn chế đó, theo các chuyên gia nghiên cứu về AI, đã bắt nguồn từ một loạt những khó khăn mang tính hệ thống trong lĩnh vực nghiên cứu ứng dụng machine learning.
Với đại dịch COVID-19, nhu cầu cấp thiết cần có giải pháp có thể đã khiến người ta "du di" các tiêu chuẩn khắt khe trong nghiên cứu khoa học.
Cho đến nay, vấn đề lớn nhất cũng là khó giải quyết nhất với các mô hình machine learning là có quá ít những bộ dữ liệu lớn, đa dạng để đào tạo cũng như đánh giá hệ thống AI. Và đặc biệt, rất nhiều trong số dữ liệu đó, dù đang có, lại được bảo mật vì lý do pháp luật hay thương mại.
Cuối tháng 5 vừa qua, Google ra mắt ứng dụng sử dụng AI phân tích các bệnh về da, nhưng cũng từ chối công khai các nguồn dữ liệu để đào tạo hệ thống. Một người phát ngôn của Google nói một số dữ liệu của họ được cấp phép lại từ các bên thứ ba hoặc do người dùng tặng, và công ty này không công khai nguồn dữ liệu theo các điều khoản thỏa thuận của họ.
Điều này cũng có nghĩa các nhà nghiên cứu bên ngoài không thể có dữ liệu để kiểm chứng các kết luận của nghiên cứu, cũng như không thể so sánh với công trình tương tự - bước quan trọng trong việc kiểm tra, đánh giá bất cứ nghiên cứu khoa học nào.
Việc không thể kiểm nghiệm các mô hình AI trên dữ liệu từ nhiều nguồn khác nhau - một quá trình thường được gọi là ngoại hiệu lực (external validation) - xảy ra khá phổ biến trong các nghiên cứu về AI.
Điều này thường dẫn tới việc thuật toán có vẻ rất chính xác trong nghiên cứu, nhưng lại không cho hiệu quả tương đương khi xử lý các yếu tố đa dạng, thường hay thay đổi của thế giới thực, như kiểu nhóm người bệnh hay dữ liệu hình chụp/quét thu được từ các thiết bị khác nhau.
"Nếu các kết quả áp dụng trong điều kiện chăm sóc lâm sàng không đạt được tiêu chuẩn như đã sử dụng trong nghiên cứu, khi đó chúng ta có nguy cơ phê chuẩn những thuật toán chúng ta không tin cậy - ông Matthew McDermott, nhà nghiên cứu tại Viện Công nghệ Massachusetts, đồng tác giả một nghiên cứu gần đây cũng về những sai sót trong hệ thống AI, nói - Rốt cuộc chúng còn có thể làm cho việc chăm sóc người bệnh tệ hơn".
Những sai sót tương tự đã xảy ra với một loạt thiết bị ứng dụng AI trong điều trị các bệnh nặng như tim và ung thư. Điều tra cuối tháng 2-2021 của chuyên trang STAT cho biết, chỉ 73/161 các sản phẩm AI được Cơ quan Quản lý thuốc và thực phẩm (FDA) Mỹ phê chuẩn đã công bố nguồn dữ liệu để bảo chứng cho sản phẩm của họ. Và chỉ 7 sản phẩm công bố các thành phần chủng tộc trong các nhóm người tham gia nghiên cứu của họ.
Tương tự, trong nghiên cứu công bố trong tạp chí Nature Medicine số tháng 4 năm nay, các nhà nghiên cứu của ĐH Stanford cũng chỉ ra sự thiếu vắng các nghiên cứu theo thời gian (nguyên văn "prospective study", chỉ những nghiên cứu phải theo dõi đối tượng trong một thời gian và thu thập tần số phát sinh bệnh trong thời gian đó) trong các sản phẩm AI đã được FDA phê duyệt.
Theo nhóm này, hầu hết các thiết bị AI đó chỉ được đánh giá tại một vài địa điểm nhỏ, và chỉ mới ghi nhận một phần nhỏ về cách thức hệ thống AI hoạt động như thế nào trong các nhóm nhân khẩu học khác nhau.
"Chúng tôi muốn AI hoạt động có trách nhiệm và tin cậy với các bệnh nhân khác nhau trong nhiều bệnh viện khác nhau - ông James Zou, giáo sư ngành khoa học dữ liệu y sinh tại ĐH Stanford, đồng tác giả của nghiên cứu này, nói - Việc có thể đánh giá và thử nghiệm các thuật toán này trên các kiểu loại dữ liệu đa dạng là đặc biệt quan trọng".
Rõ ràng đến thời điểm này, AI đã hỗ trợ con người trong nhiều lĩnh vực, đặc biệt là phòng chống đại dịch Covid-19, nhưng nó vẫn chưa là phép màu mà cần phải được tiếp tục nghiên cứu, hoàn thiện.
Giải pháp nào cho vấn đề dữ liệu?
Theo nhà nghiên cứu Matthew McDermott, có một số cách để chia sẻ dữ liệu phục vụ nghiên cứu, phát triển AI trong y tế mà không vi phạm quyền riêng tư hay quyền sở hữu trí tuệ. Chẳng hạn có thể sử dụng phương pháp học liên kết, trong đó các đơn vị có thể cùng đào tạo một thuật toán trên nhiều thiết bị hoặc máy chủ phi tập trung chứa các mẫu dữ liệu cục bộ mà không phải trao đổi các dữ liệu đó. Hay cũng có thể sử dụng dữ liệu tổng hợp được lấy mẫu từ người bệnh thực tế để bảo vệ quyền riêng tư.




Tối đa: 1500 ký tự
Hiện chưa có bình luận nào, hãy là người đầu tiên bình luận